Bonjour,
@pauline.gourlet et moi sommes ravis de vous partager la mise à disposition d’un nouvel outil, Corpora !

Pour quoi faire ?
Corpora est un outil de création et de gestion d’archives numériques, c’est-à-dire de collection de documents numériques hétérogènes. Idéal pour collaborer et centraliser de la veille ou constituer un fond documentaire partagé, il a comme principe de base la génération de « fiches » appelées fragments (ou récits). Ces fragments forment une archive consultable, organisée par leur contenu ou classée à partir de mots-clés et de catégories décidée par leurs auteurs. Il est également possible de créer et de décrire des « collections » à partir d’une sélection de fragments, l’idée étant de permettre de revisiter l’archive et d’ouvrir son organisation à d’autres personnes, non auteurs.
Comment ?
Chaque fragment peut contenir un nombre illimité (en théorie ![]() ) de médias : textes, images, vidéos (fichier local ou intégration youtube et vimeo), sons, URL de sites web, ou autres fichiers. Corpora se veut simple, facile à prendre en main et collaboratif, pensé pour des utilisations variés (smartphones et tablettes, ordinateurs récents ou sur une vieille machine, etc.). Comme la plupart de nos outils/logiciels, il existera deux version :
) de médias : textes, images, vidéos (fichier local ou intégration youtube et vimeo), sons, URL de sites web, ou autres fichiers. Corpora se veut simple, facile à prendre en main et collaboratif, pensé pour des utilisations variés (smartphones et tablettes, ordinateurs récents ou sur une vieille machine, etc.). Comme la plupart de nos outils/logiciels, il existera deux version :
- une version en ligne, hébergée sur un serveur sur internet — le tuto Installer do•doc sur un serveur dédié s’applique
- une version hors ligne, permettant de collaborer sur un réseau local
Et comme tous nos outils, ces deux versions respectent autant que possible la vie privée : pas de cookies, pas de suivi des visites, aucun appel aux sites “intégrés” type youtube et vimeo sans action de l’utilisateur, notamment.
D’ailleurs Corpora a été l’occasion de développer une brique côté server qui permet d’aller chercher les données d’un site tiers (titre, description, et image d’aperçu) pour les afficher dans l’interface sans charger le site à chaque fois — Facebook, Twitter ou Discourse qui gère ce forum le font déjà, mais ça manquait pour pouvoir afficher ces données sans en informer le site original à chaque fois. À terme cela pourra permettre aux autres outils comme do•doc d’importer un site ou une image (libre de droit bien sur) à partir d’un lien, par exemple.
Contexte
Cet outil est bien sûr libre et open-source, son code source se trouve sur GitHub - l-atelier-des-chercheurs/Corpora.
Il a été créé avec et pour l’association réseau Université de la Pluralité : Daniel Kaplan, Chloé Luchs-Tassé, Virginie Gauthier et Rose Rondelez. Son développement a démarré il y a 2 ans, le 26 mars 2020, et il y a déjà eu plusieurs refontes avant d’arriver à la version disponible aujourd’hui.
Quelques captures d’écran et un lien pour tester ci-dessous :
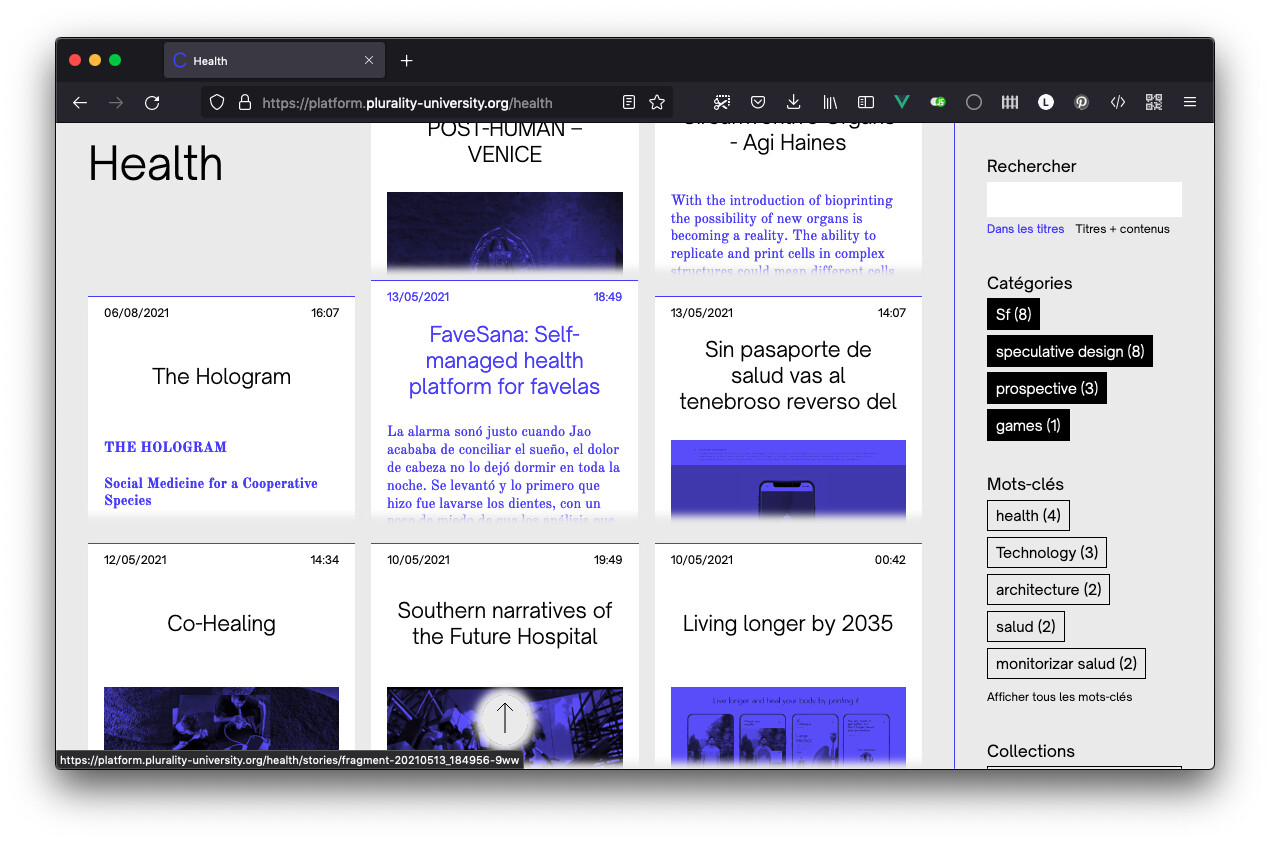
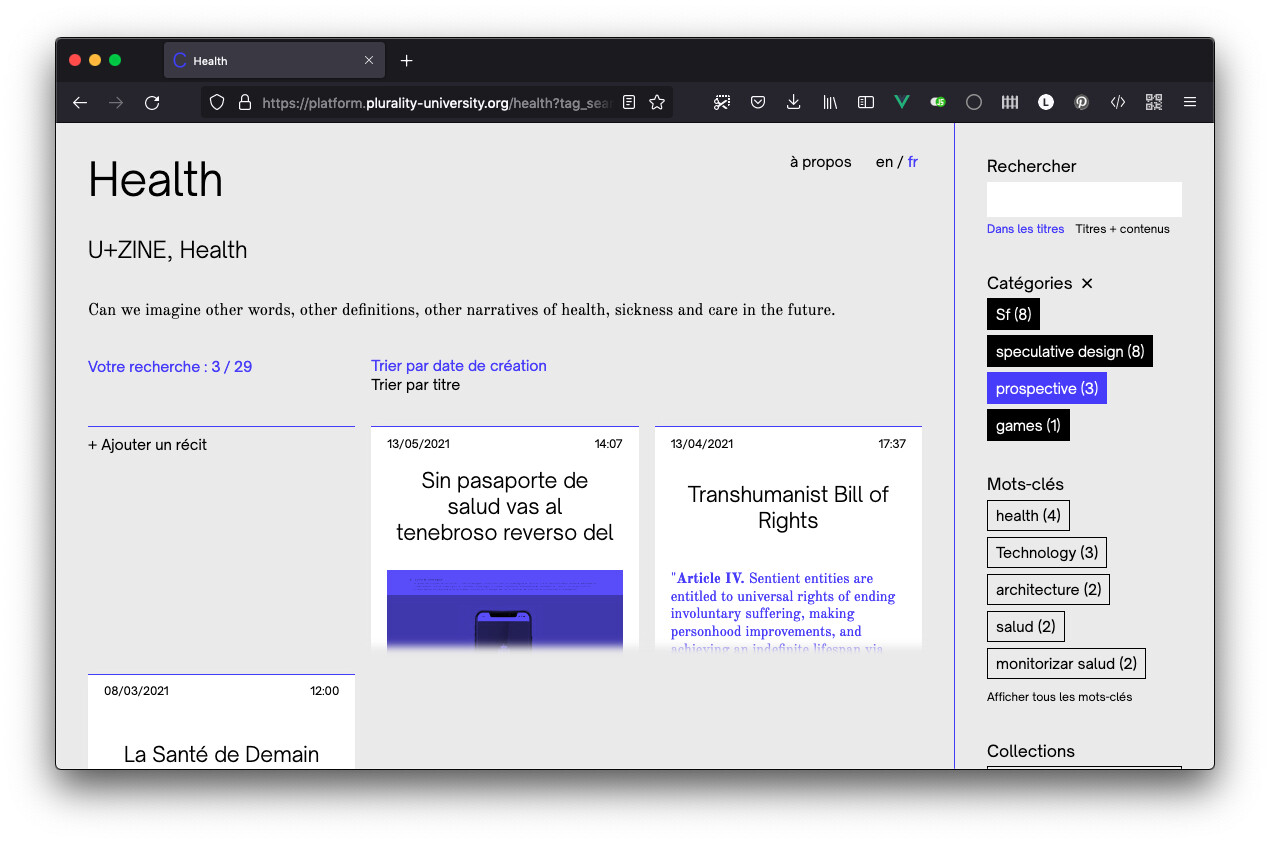
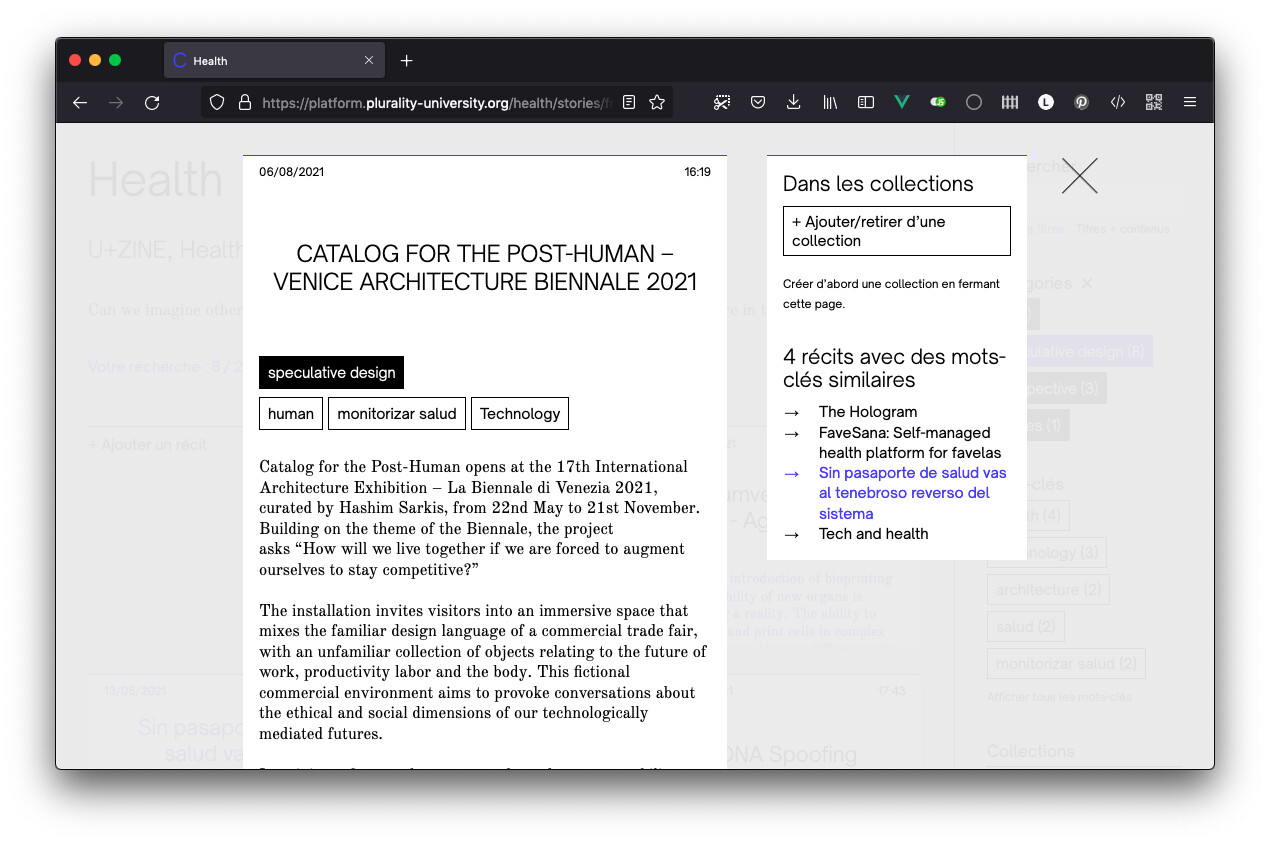
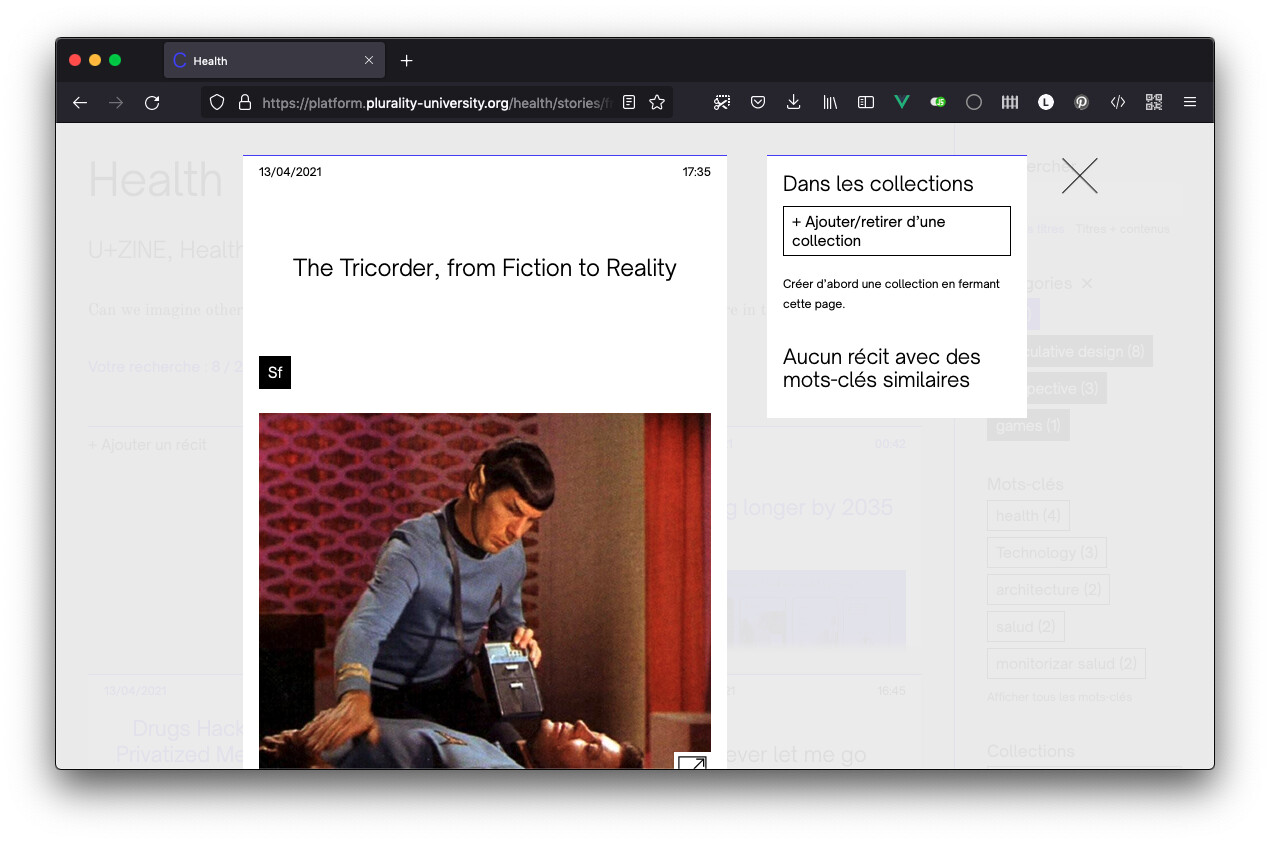
Pour consulter un corpus avec plus de 200 récits (et plus de 1000 traces individuelles) :
https://platform.plurality-university.org/narratopia/
Et un peu de contexte sur le site de réseau Université de la Pluralité : Narratopias : imagine the worlds we want | Plurality University Network
Enfin, voici un lien où vous pouvez tester tout ça : testez ici Corpora.
N’hésitez pas à poster ici vos retours, impressions et questions ![]()